OCaml first hit my radar in November 2013. I had just learnt SML, a similar but older language, in the excellent Programming Languages Coursera course. Dan Grossman is one of the best lecturers I’ve ever seen, I found his explanations hit all the right notes and made learning easy. The simplicity of the SML syntax, and the power of the language while still producing code that is readable with minimal training immediately appealed to me.
Over the last 3 years I have tried, and failed, to learn Haskell. The combination of minimalist syntax, pure functional programming style and lazy evaluation is like a 3-hit sucker punch that is very hard to grasp all at once. Having now learnt SML and OCaml, which like Haskell are based on the ML language, that has changed. I have yet to put any more effort into learning Haskell, but it is now clear to me that the syntax is only a small leap from ML and the pure functional style has similarities to SML.
I still don’t want to write production code in Haskell, but the fact that I find it less scary than I used to indicates I have made a significant jump in my knowledge and, arguably, career in the last 6 months.
Dynamic typing
Before I go any further, I need fans of dynamic typing to exit the room. My 12 years in the industry have set my camp firmly on the static typing side of the fence, and discussions about static vs dynamic will not be productive or welcome here.
So, why OCaml?
Smarter people than me have written about this, but I’ll give it a shot.
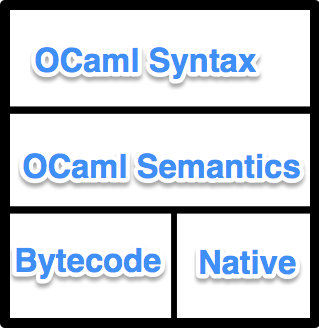
I have found OCaml to be a refreshing change of pace. Most of my favourite things are derived from the ML base language; variants, records, and pattern matching combine to create elegantly powerful code that is still easy to follow (unlike most Haskell code I’ve seen).
Ocaml takes the expression-based ML style and incorporates enough imperative features to make it comfortable for someone learning Functional Programming. Don’t know how to use recursion to solve a problem? Drop into a for loop in the middle of your expression. Need some debug output? Add it right there with a semicolon to sequence expressions.
Throw in almost perfect static type inference, a compiler that gives useful error messages and immutable-by-default variables and I just can’t get enough. I won’t sit here and list every feature of the language, but hopefully that piques your interest as much as it did mine 😉
Industry acceptance
There is always an element of “I have a hammer, everything looks like a nail” when learning a new language but the evidence that OCaml is becoming more widely accepted is not hard to find.
In the middle of February, Thomas Leonard’s OCaml: what you gain post made waves; the reddit and hackernews discussions are fascinating. A lot of people using OCaml in the industry came out of the woodwork for that one. I’m still working my way through the series of 11 posts Thomas made, dating back to June 2013, about his process of converting a large Python codebase to OCaml.
Facebook have a fairly extensive OCaml codebase (more details below).
It doesn’t take much googling to find presentations by Skydeck in 2010 (they wrote ocamljs, the first ocaml to JS compiler) or a 2006 talk describing why OCaml is worth learning after Haskell.
OCamlPro appear to be seeing good business out of OCaml, and they have an excellent browser-based OCaml tutorial (developed using, of course, js_of_ocaml).
No list of OCaml developers would be complete without mentioning the immense amount of code at Jane Street.
There are plenty of other success stories.
The elephant in the room
The first question I usually get when I tell a Functional Programming guru that I’m learning OCaml is “Why not Haskell?”. It’s a fair enough question. Haskell can do a ton more than OCaml can, and there are only one or two things OCaml can do that Haskell can’t (I don’t know the details exactly, I would think it was zero). I see a lot of references to OCaml being a gateway drug for Haskell.
The answer is JavaScript. As much as I hate the language, JS is the only realistic way to write web apps. Included in the many and varied AltJS languages, both OCaml and Haskell can be compiled to JavaScript but the Haskell compilers aren’t mature enough yet (and I’m not convinced lazy evaluation in JavaScript will have good performance).
In fact, some study has revealed OCaml may be the most mature AltJS compiler of all by virtue of support for existing OCaml libraries.
JavaScript
Late last year I started hearing about OCaml at Facebook. Their pfff tool, which is a serious OCaml codebase all by itself, is already open source – but there was talk of an even larger project using js_of_ocaml (the link seems to be offline, try the video). That presentation by Julien Verlaguet is almost identical to the one he gave at YOW! 2013 and it really grabbed my attention. (Hopefully the YOW! video is online soon, as it’ll be better quality).
To cut a long story short, Facebook created a new language (Hack, a statically typed PHP variant) and wrote the compiler in OCaml. They then use js_of_ocaml to compile their entire type checker into JavaScript, as the basis of a web IDE (@19 minutes in the video) along the lines of cloud9. Due to the use of OCaml for everything, this IDE has client-side code completion and error checking. It’s pretty amazing.
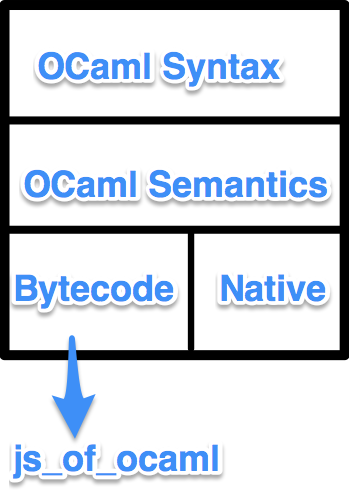
Maturity of tools and js_of_ocaml
The more I dive into OCaml, and specifically js_of_ocaml, the more it amazes me how the maturity of the tools and information reached suitability for production use just as I need them.
-
The package manager OPAM is now a little over 12 months old and every library I’ve looked at is available on it. Wide community acceptance of a good package manager is a huge plus.
-
The Real World OCaml book was released in November and is an excellent read. The book is so close to the cutting edge they had features added to September’s 4.01.0 compiler release for them 🙂
-
OCaml Labs has been around for 12 months, and they’re helping to move the OCaml community forward into practical applications (see the 2013 summary).
-
Ocsigen are investing heavily in js_of_ocaml (among other things) with the next release including an improved optimiser (I can attest to the fact that it’s awesome) and support for FRP through the React library.
Moving forward
Is it perfect? No. Software development is not a one-size-fits-all industry. There are as many articles cursing the limitations of OCaml as there are singing its praises. But in the current market, and with the size of JavaScript applications we are starting to generate, I believe OCaml has a bright future.